EDA (Exploratory Data Analysis)
탐색적 자료분석
데이터를 분석하는 기술적 접근은 많다.
그래서 방법론에 집중하다보면 데이터가 가진 본질적인 의미를 훼손할 수 있다.
EDA \(\rightarrow\) 데이터 그 자체만으로부터 인사이트를 얻어내는 접근법
EDA 과정에서는 다음과 같은 과정이 포함됨
- 시각화 과정
- 통계적 수치 (통계학)
- 자료를 담는 numpy, pandas
EDA의 Process
- 분석의 목적과 변수 확인
- 분석의 목적 : 분석 후 결과에 대한 의미 도출
- 변수 확인 : 각 컬럼들이 어떤 의미를 가지며 어떤 타입을 가지고 있고, 분석하는 데에 적절한지 확인
- 데이터 전체적으로 살펴보기
- 데이터간의 상관관계, 결측치(NA), 데이터의 사이즈(일반화하기에 적절히 큰지) 파악
- 데이터의 개별 속성 파악하기
- 각 데이터의 개별 속성 (같은 값이어도 어느 컬럼에 들어가 있냐에 따라 달라짐) 파악
EDA Example - Titanic Problem
분석의 목적과 변수 확인
- 분석의 목적
- 데이터에는 탑승색 정보와 그 사람의 생존 여부가 들어있다.
- 그렇다면, 살아남은 사람들은 어떤 특징을 가지고 있을까?
- 변수 확인
- Variable : 열 이름
- Definition : 열에 대한 정보
- key : 숫자로 인코딩되어있는 경우 그 숫자가 무엇을 나타내는 지를 뜻함

- Survived : 생존 여부 (0=Dead, 1=Survived)
- Pclass : 탑승 티켓의 등급 (1=1st, 2=2nd, 3=3rd)
- Sex : 성별
- Age : 나이
- Variable Notes - 1살보다 어리면 분수로, 추정치라면 xx.5로 표현됨
- SibSp : 형제자매나 배우자가 몇명이 타고 있는지
- Parch : 부모님이나 자식이 몇명이 타고 있는지
- Ticket : 티켓 번호
- Fare : 탐승객이 지불한 요금
- Cabin : 승무원 번호
- Embarked : 탐승한 항구
Exploratory Data Analysis
탐색적 데이터 분석을 통해 데이터를 통달해봅시다.
- 라이브러리 준비
- 분석의 목적과 변수 확인
- 데이터 전체적으로 살펴보기
- 데이터의 개별 속성 파악하기
0. 라이브러리, 데이터 준비
# 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline# 데이터 블러오기
# 동일 경로에 "train.csv"가 있는 경우
titanic_df = pd.read_csv("./train.csv")
1. 분석의 목적과 변수 확인
- 타이타닉 호에서 생존한 생존자들은 어떤 사람들일까?
# 상위 5개 데이터 확인하기
titanic_df.head(5)- Cabin 에 결측치(NA)가 존재하는 것에 유의
- 결측치가 의미하는 바에 따라 처리해주어야 함


2. 데이터 전체적으로 살펴보기
수치형 데이터 요약 보기
DataFrame.describe()- 수치형 데이터만 요약해주기 때문에 Name, Ticket 와 같은 object 자료형은 제공하지 않는다.
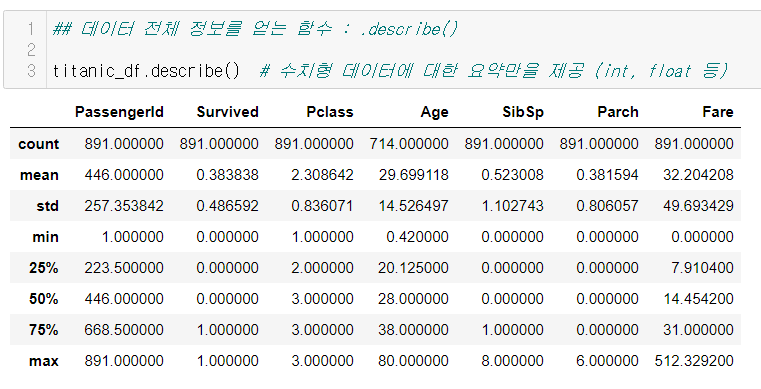
count(개수), mean(평균), std(표준편차), min(최소), Q(백분위), max(최대)
- PassengerId
- 인덱스이기 때문에 큰 의미없다
- Survived
- 0, 1로 구성되어있는 이진데이터
- (가설) 평균이 0.5보다 작기 때문에 생존하지 못한 사람이 더 많을 것이다.
- Pclass
- 범주형 데이터이기 때문에 큰 의미를 가지지 않는다.
- Age
- 평균 29.5, 표준편차 14.5, 최소나이 0.4, 최대나이 80
- SibSp
- 최대 8
- Parch
- 최대 6
- Fare
- (가설) 평균 32.2, 표준편차 49인데, 최소가 0이고 최대가 512인 것은 차이가 너무 크므로 이상점(outlier)라고 볼 수 있다
상관관계 확인
DataFrame.corr()- \(x_1\)과 \(x_2\)의 상관관계

- Pclass - Fare
- 높은 등급일수록 요금이 비쌀 수 있다.
- Pclass - Survived
- 높은 등급의 사람들의 생존율이 더 높을 수 있다.
주의) Correlation is NOT Causation
- 상관성 : A up, B up, ...
상관성이 높게 나온다하더라도 인과성이 성립하는 것은 아니다. - 인과성 : A -> B (원인과 결과)
인과성을 증명하는 것은 어려운 일
결측치 확인
DataFrame.isnull()- 통계함수(sum())를 이용하면 보기 편하다
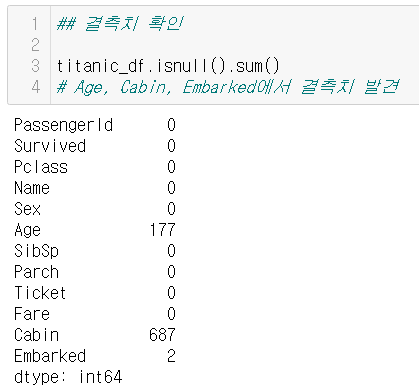
\(\Rightarrow\)결측치를 어떻게 처리할 지 정해야 함
- 특정 값으로 대체할지
- 하나의 데이터로 판단할지
- 제거할지
3. 데이터의 개별 속성 파악하기
I. Survived column


II. Pclass


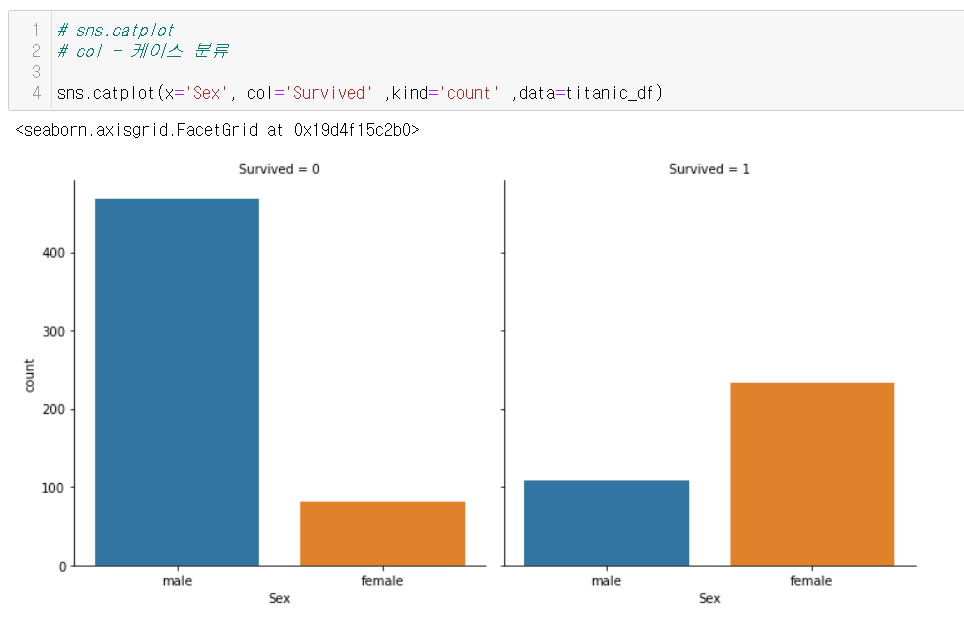
III. Sex



IV. Age


Appendix
I. Sex + Pclass VS Survived
- 복잡한 요소를 표현할 때에는 catplot을 많이 사용
hue 옵션을 추가하면 특정 컬럼을 기준으로 나눠서 파악하기 용이
그래프는 pclass 별 생존자에 대한 추정치를 나타냄
\(\Rightarrow\) pclass가 높을 수록 생존자인 비율이 더 높다!


II. Age+Pclass VS Survived
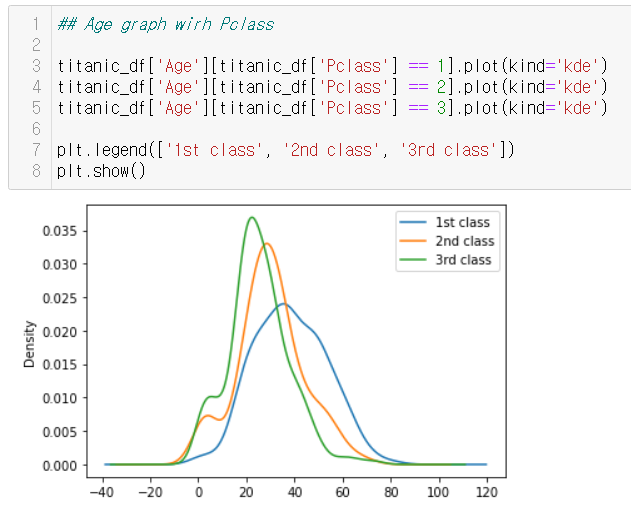
\(\Rightarrow\) 클래스가 높은 등급일수록 나이대가 높다!
정리)
- 데이터를 뽑아봅시다.
- 각 데이터는 어떤 자료형을 가지고 있나요?
- 데이터에 결측치는 없나요? -> 있다면 이를 어떻게 메꿔줄까요?
- 데이터의 자료형을 바꿔줄 필요가 있나요? -> 범주형의 One-hot encoding
- 데이터의 대한 가설을 세워봅시다.
- 가설은 개인의 경험에 의해서 도출되어도 상관이 없습니다.
- 가설은 명확할 수록 좋습니다. ex) Titanic Data에서 Survived 여부와 성별에는 상관관계가 있다.
- 가설을 검증하기 위한 증거를 찾아봅시다.
- 이 증거는 한 눈에 보이지 않을 수 있습니다. 우리가 다룬 여러 Technique를 써줘야합니다.
- `.groupby()` 를 통해서 그룹화된 정보에 통계량을 도입하면 어떨까요?
- `.merge()` 를 통해서 두 개 이상의 DataFrame을 합치면 어떨까요?
- 시각화를 통해 일목요연하게 보여주면 더욱 좋겠죠?
'프로그래머스인공지능스쿨' 카테고리의 다른 글
| [5주차 - Day2] Django으로 동적 웹 페이지 만들기 (0) | 2021.05.18 |
|---|---|
| [5주차 - Day1] Web Application with Django (0) | 2021.05.17 |
| [4주차 - Day2] 클라우드를 활용한 머신러닝 모델 Serving API 개발 (0) | 2021.05.11 |
| [4주차 - Day1] Web Application with Flask (0) | 2021.05.11 |
| [3주차 - Day4] Python으로 시각화하기 - Matplotlib (0) | 2021.05.06 |